Datenanreicherung im KI-Zeitalter: Warum gute n8n-Prozesse vor dem Workflow beginnen
KI macht Automatisierung leistungsfähiger. Aber sie ersetzt keine saubere Datenerfassung, Prüfung und Freigabe. Gerade deshalb gewinnen Open-Source-Werkzeuge zur Datenanreicherung an Bedeutung.
Automatisierung beginnt oft mit einer technischen Frage:
Wie kann ich diesen Prozess in n8n automatisieren?
Das ist verständlich. n8n ist ein starkes Werkzeug, um Systeme zu verbinden, Daten weiterzugeben, APIs anzusprechen, KI-Dienste einzubinden, E-Mails zu versenden, Tickets zu erstellen oder CRM-Systeme zu befüllen.
Die wichtigere Frage kommt aber meistens früher:
Wie kommen eigentlich gute, vollständige und verwertbare Daten in diesen Prozess?
Genau an dieser Stelle entscheidet sich, ob ein Workflow später stabil läuft oder ständig manuelle Nacharbeit verursacht. Ein n8n-Workflow kann noch so sauber gebaut sein: Wenn die Eingangsdaten unvollständig, unklar oder widersprüchlich sind, wird auch die beste Automatisierung unsicher.
Im KI-Zeitalter wird dieses Thema noch wichtiger. Denn KI kann zwar Texte verstehen, Inhalte zusammenfassen, Daten klassifizieren und Vorschläge machen. Aber KI ersetzt keine Datenqualität.
Im Gegenteil: Je stärker KI in Geschäftsprozesse eingebunden wird, desto wichtiger wird eine saubere Datenbasis.
Ein guter Workflow beginnt deshalb nicht mit einem Prompt.
Er beginnt mit guten Eingangsdaten.
🤖 KI löst nicht automatisch das Datenproblem
Künstliche Intelligenz kann beeindruckend viel leisten. Sie kann Freitexte analysieren, Kundenanfragen zusammenfassen, Inhalte kategorisieren, Antwortvorschläge erstellen oder Informationen aus Dokumenten extrahieren.
Das verleitet schnell zu der Annahme, dass strukturierte Datenerfassung weniger wichtig wird. Schließlich könnte man doch einfach einen Freitext an eine KI übergeben und die KI macht daraus schon etwas Brauchbares.
In einfachen Tests funktioniert das oft erstaunlich gut.
In produktiven Geschäftsprozessen reicht das aber nicht.
Ein Beispiel:
Ein Kunde schreibt in ein Formular:
„Ich brauche Unterstützung bei der Digitalisierung.“
Das klingt zunächst brauchbar. Für eine KI ist daraus vielleicht ableitbar, dass es um Beratung, Automatisierung oder Prozessoptimierung geht.
Aber für einen belastbaren Geschäftsprozess fehlen wichtige Informationen:
- Geht es um ein Unternehmen, einen Verein oder eine Einzelperson?
- Welcher Bereich ist betroffen?
- Gibt es bereits bestehende Systeme?
- Ist das Anliegen dringend?
- Wurde ein Budget genannt?
- Darf bereits ein Angebot vorbereitet werden?
- Wer ist zuständig?
- Soll ein Ticket, ein CRM-Eintrag oder eine Wiedervorlage entstehen?
Wenn diese Informationen fehlen, muss die KI raten oder der Workflow muss mit unsicheren Annahmen arbeiten. Beides ist problematisch.
🤖 KI kann fehlende Informationen plausibel ergänzen. Aber plausibel ist nicht dasselbe wie korrekt.
🧱 Datenqualität ist keine technische Nebensache
Datenqualität entscheidet darüber, ob Automatisierung zuverlässig ist.
Gute Daten sind:
- vollständig,
- strukturiert,
- eindeutig,
- plausibel,
- aktuell,
- nachvollziehbar,
- freigegeben.
Schlechte Daten führen dagegen zu unsicheren Ergebnissen. Das gilt für klassische Automatisierung genauso wie für KI-gestützte Prozesse.
Ein n8n-Workflow kann beispielsweise automatisch ein Ticket erzeugen, eine E-Mail schreiben und einen CRM-Eintrag anlegen. Wenn aber die Kategorie falsch ist, die Kontaktdaten fehlen oder die Anfrage nicht geprüft wurde, wird der Fehler nur schneller verteilt.
Automatisierung verstärkt also nicht nur gute Prozesse.
Sie verstärkt auch schlechte Daten.
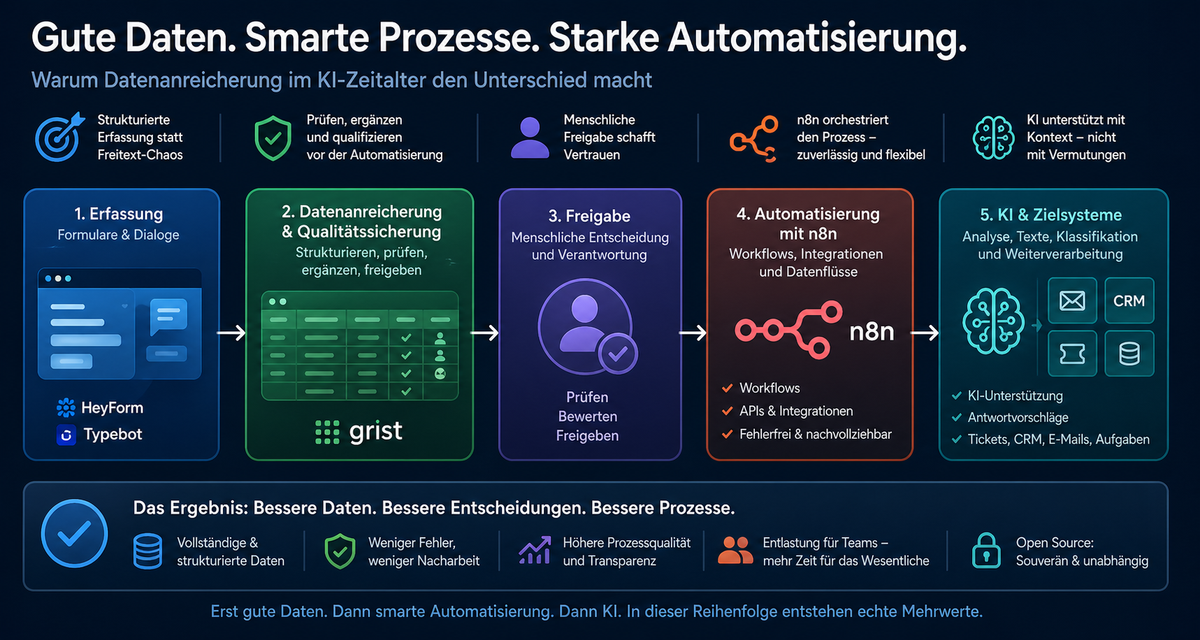
Deshalb braucht es vor der eigentlichen Automatisierung eine Schicht, die Daten strukturiert, ergänzt und absichert.
Diese Schicht nenne ich hier: Datenanreicherung und Qualitätssicherung vor n8n.
🧱 Datenqualität ist das Fundament jeder verantwortbaren Automatisierung.
🔎 Was bedeutet Datenanreicherung in diesem Zusammenhang?
Datenanreicherung bedeutet nicht nur, externe Informationen aus anderen Systemen hinzuzufügen.
Im Kontext von n8n-Prozessen meint Datenanreicherung vor allem:
- Rohdaten in eine klare Struktur bringen,
- Pflichtangaben erfassen,
- fehlende Informationen sichtbar machen,
- Auswahlfelder statt unklarer Freitexte verwenden,
- Kategorien und Statuswerte ergänzen,
- Datensätze manuell prüfen,
- Zuständigkeiten festlegen,
- Freigaben dokumentieren,
- Daten für die Übergabe an n8n vorbereiten.
Ein einfacher Freitext wird dadurch zu einem nutzbaren Datensatz.
Aus:
„Wir brauchen Hilfe mit unseren Abläufen.“
wird zum Beispiel:
Anliegen: Prozessautomatisierung
Bereich: Verwaltung
Organisationstyp: Unternehmen
Dringlichkeit: mittel
Vorhandene Systeme: Outlook, Excel, CRM
Ziel: weniger manuelle Datenerfassung
Nächster Schritt: Erstgespräch vereinbaren
Freigabestatus: geprüft
Zuständig: Beratung
Mit solchen Daten kann n8n zuverlässig arbeiten.
Und auch eine KI bekommt dadurch einen deutlich besseren Kontext.
⚠️ Warum KI Struktur nicht ersetzt
KI ist stark in Interpretation, Formulierung und Mustererkennung.
Aber KI ist kein Ersatz für:
- Pflichtfelder,
- Datenmodelle,
- Berechtigungen,
- Zuständigkeiten,
- Statuswerte,
- Prüfschritte,
- Freigaben,
- Protokollierung,
- Verantwortlichkeit.
Gerade diese Elemente sind aber für produktive Prozesse entscheidend.
Ein Unternehmen kann nicht einfach sagen:
„Die KI hat das so verstanden.“
Es muss nachvollziehbar bleiben:
- Wer hat die Information eingegeben?
- Wann wurde sie erfasst?
- Welche Angaben wurden geprüft?
- Welche Felder wurden automatisch ergänzt?
- Welche Daten wurden an die KI übergeben?
- Welche Entscheidung wurde automatisiert vorbereitet?
- Wo war menschliche Freigabe erforderlich?
Ohne diese Struktur wird KI schnell zu einer Blackbox im Prozess.
Mit einer sauberen Datenanreicherungsschicht wird KI dagegen kontrollierbar und sinnvoll nutzbar.
💬 Nicht alles sollte ein Prompt sein
Ein häufiger Denkfehler im KI-Zeitalter lautet:
Wenn die Daten unstrukturiert sind, bauen wir einfach einen besseren Prompt.
Das kann kurzfristig helfen. Langfristig ist es aber keine stabile Prozessarchitektur.
Prompts können unterstützen. Sie können Informationen interpretieren, Texte generieren oder Klassifikationen vorschlagen. Aber sie sollten nicht die fehlende Grundstruktur eines Prozesses ersetzen.
Wenn jedes Problem durch einen immer längeren Prompt gelöst werden soll, entsteht eine schwer wartbare Automatisierung. Dann steckt die eigentliche Prozesslogik nicht mehr sauber in Datenmodellen, Feldern, Statuswerten oder Freigaben, sondern in Textanweisungen an eine KI.
Das ist fragil.
Besser ist ein anderer Ansatz:
klare Eingabestruktur
+ geprüfte Daten
+ definierte Statuswerte
+ kontrollierte Übergabe
+ gezielter KI-Einsatz
= stabile Automatisierung
KI sollte auf guter Prozessstruktur aufbauen.
Sie sollte diese Struktur nicht ersetzen müssen.
💬 Ein guter Prozess wird nicht dadurch besser, dass man schlechte Eingangsdaten mit einem immer längeren Prompt repariert.
🛠️ Die Rolle spezialisierter Open-Source-Werkzeuge
An dieser Stelle kommen spezialisierte Werkzeuge ins Spiel.
Es geht nicht darum, möglichst viele Tools einzusetzen. Es geht darum, die richtigen Rollen im Prozess sauber zu besetzen.
In einem Open-Source-orientierten Stack können solche Werkzeuge unterschiedliche Aufgaben übernehmen:
- Formulare erfassen strukturierte Eingaben.
- Dialogsysteme führen Nutzer Schritt für Schritt durch komplexere Fragen.
- Datenpflegewerkzeuge ermöglichen Prüfung, Ergänzung und Freigabe.
- n8n orchestriert anschließend den automatisierten Prozess.
- KI unterstützt dort, wo Interpretation, Zusammenfassung oder Textgenerierung sinnvoll ist.
Die Werkzeuge ersetzen n8n nicht.
Sie verbessern die Datenbasis, auf der n8n arbeitet.
Und sie ersetzen auch keine KI.
Sie sorgen dafür, dass KI mit besseren, kontrollierbaren Informationen arbeitet.
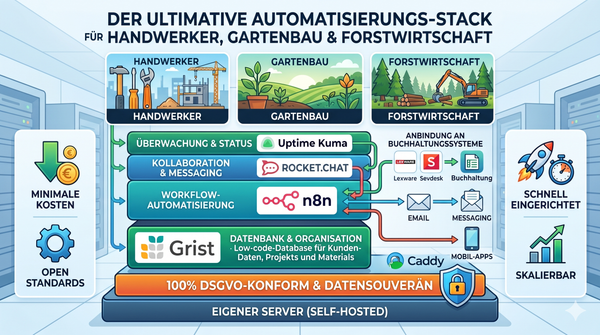
🔄 n8n als Orchestrierungsschicht
n8n ist in dieser Architektur nicht das Formularsystem, nicht die Datenbank und nicht die menschliche Prüfstelle.
n8n ist die Orchestrierungsschicht.
Das bedeutet:
n8n verbindet Systeme, löst Workflows aus, verarbeitet Daten, steuert Übergaben und bindet KI-Dienste oder Zielsysteme ein.
Eine sinnvolle Architektur kann so aussehen:
Kunde / Mitarbeiter / Website
↓
Formular oder Dialog
↓
strukturierte Datenpflege und Anreicherung
↓
n8n
↓
KI-Unterstützung
↓
CRM / Ticketsystem / E-Mail / Dokument / Aufgabe
In einer konkreten Open-Source-Umgebung kann das beispielsweise so aussehen:
HeyForm oder Typebot
↓
Grist
↓
n8n
↓
KI + Zielsysteme
Die Namen der Werkzeuge sind dabei nicht der eigentliche Kern. Entscheidend ist die Rollenverteilung:
Erst erfassen. Dann strukturieren. Dann prüfen. Dann automatisieren. Dann KI gezielt einsetzen.
🔄 n8n automatisiert den Ablauf, aber die Qualität entsteht bereits vor dem Workflow.
🧪 Umsetzung im Innovation Lab von gerds-it.de
Im Innovation Lab von gerds-it.de wird genau dieser Ansatz praktisch erprobt: Open-Source-Werkzeuge übernehmen jeweils klar definierte Rollen im Prozess und werden zu einem nachvollziehbaren, selbst hostbaren Automatisierungsstack verbunden.
n8n bildet dabei die zentrale Orchestrierungsschicht, mit der Datenflüsse, APIs, KI-Dienste und Zielsysteme zu durchgängigen Prozessen verbunden werden.
Grist dient als strukturierte Datenpflege- und Anreicherungsschicht, in der Informationen geprüft, ergänzt, freigegeben und für die weitere Automatisierung vorbereitet werden.
Typebot ermöglicht dialogische Datenerfassung, bei der Nutzer Schritt für Schritt durch Fragen geführt werden und aus freien Eingaben strukturierte Prozessdaten entstehen.
HeyForm ergänzt den Stack um klassische Formulare, Umfragen und strukturierte Eingabemasken für einfache, schnelle und nachvollziehbare Datenerfassung.
Zusammen entsteht daraus ein praxisnaher Open-Source-Best-of-Breed-Ansatz: Die Daten werden sauber erfasst, kontrolliert angereichert und erst danach über n8n automatisiert weiterverarbeitet.
✅ Qualitätssicherung vor Automatisierung
Gute Automatisierung bedeutet nicht, dass alles sofort automatisch weiterläuft.
Gute Automatisierung bedeutet, dass der richtige Schritt zum richtigen Zeitpunkt passiert.
Manche Daten können direkt verarbeitet werden. Andere brauchen eine Prüfung. Wieder andere müssen ergänzt, bewertet oder freigegeben werden.
Ein sinnvoller Ablauf kann deshalb so aussehen:
1. Anfrage wird über Formular oder Dialog erfasst
2. Datensatz wird strukturiert abgelegt
3. Pflichtfelder und Plausibilität werden geprüft
4. Fehlende Informationen werden ergänzt
5. Optional unterstützt KI bei Zusammenfassung oder Klassifikation
6. Ein Mensch gibt den Datensatz frei
7. n8n startet den eigentlichen Folgeprozess
Das ist kein Rückschritt gegenüber Automatisierung.
Es ist professionelle Prozessgestaltung.
Denn nicht jeder Prozess sollte blind durchlaufen. Besonders dann nicht, wenn KI beteiligt ist oder wenn aus den Daten konkrete Aktionen entstehen: Angebote, Tickets, Verträge, E-Mails, Aufgaben oder Entscheidungen.
✅ Erst wenn Daten vollständig, geprüft und freigegeben sind, sollten sie automatisiert weiterverarbeitet werden.
🚀 KI wird durch strukturierte Daten besser
KI profitiert enorm von guten Eingangsdaten.
Ein unscharfer Freitext zwingt die KI zur Interpretation. Ein strukturierter Datensatz gibt ihr Orientierung.
Vergleich:
Freitext:
"Wir brauchen Hilfe bei unseren Abläufen und wollen etwas automatisieren."
Strukturierte Daten:
Thema: Prozessautomatisierung
Bereich: Kundenservice
Problem: manuelle Übertragung von E-Mail-Anfragen ins CRM
Ziel: automatische Erfassung und Antwortvorschlag
Systeme: Outlook, CRM, Excel
Priorität: hoch
Freigabe: Erstprüfung abgeschlossen
Im zweiten Fall kann die KI deutlich gezielter arbeiten. Sie kann bessere Zusammenfassungen erstellen, passendere Antwortvorschläge formulieren und den Vorgang sinnvoller klassifizieren.
Die KI wird also nicht weniger wichtig.
Sie wird besser einsetzbar.
Datenanreicherung ist damit keine Konkurrenz zu KI.
Sie ist eine Voraussetzung für verlässliche KI-Nutzung.
🚀 KI wird nicht durch strukturierte Daten eingeschränkt. Sie wird dadurch besser steuerbar.
🔓 Open Source als bewusste Entscheidung
Gerade bei Datenanreicherung und KI spielt Open Source eine wichtige Rolle.
Denn hier geht es häufig um sensible Informationen:
- Kundendaten,
- interne Prozesse,
- Beratungsanfragen,
- Angebotsdaten,
- Supportfälle,
- Projektdaten,
- organisatorische Entscheidungen.
Wer solche Daten verarbeitet, sollte sich fragen:
- Wo liegen die Daten?
- Wer betreibt die Systeme?
- Welche Schnittstellen werden genutzt?
- Kann die Lösung selbst gehostet werden?
- Bleibt die Datenhoheit erhalten?
- Gibt es Abhängigkeiten von einzelnen Plattformanbietern?
- Sind Exporte und Integrationen möglich?
Ein Open-Source-Best-of-Breed-Ansatz bietet hier Vorteile.
Nicht, weil Open Source automatisch besser ist. Sondern weil offene, selbst hostbare Werkzeuge mehr Kontrolle ermöglichen. Sie reduzieren Abhängigkeiten und erlauben eine Architektur, bei der jedes Werkzeug eine klar definierte Aufgabe erfüllt.
🔓 Open Source schafft Kontrolle über Daten, Prozesse und Integrationen.
🧩 Best of Breed statt Alles-in-einem
Best of Breed bedeutet nicht, wahllos viele Werkzeuge zu kombinieren.
Es bedeutet, pro Aufgabe das passende Werkzeug zu wählen.
Für n8n-Prozesse kann das bedeuten:
Formularwerkzeug:
strukturierte Erfassung
Dialogwerkzeug:
geführte Bedarfsermittlung
Datenpflegewerkzeug:
Anreicherung, Prüfung, Freigabe
n8n:
Automatisierung und Integration
KI:
Zusammenfassung, Klassifikation, Textvorschläge, Assistenz
Der Vorteil liegt in der Klarheit.
Jedes Werkzeug bleibt in seiner Kernaufgabe. n8n muss nicht zur vollständigen Benutzeroberfläche umgebaut werden. Die KI muss keine fehlende Datenstruktur ausgleichen. Und Menschen behalten dort die Kontrolle, wo Prüfung und Verantwortung notwendig sind.
Das Ergebnis ist ein stabilerer, transparenterer und besser wartbarer Prozess.
🧩 Best of Breed bedeutet nicht mehr Tools, sondern klarere Rollen.
📥 Beispiel: Von der Anfrage zum qualifizierten Datensatz
Ein typischer Prozess könnte so aussehen:
Ein Interessent stellt über die Website eine Anfrage.
Zunächst werden die wichtigsten Informationen über ein Formular oder einen Dialog erfasst:
- Name,
- Organisation,
- Kontaktdaten,
- Anliegen,
- betroffener Bereich,
- Dringlichkeit,
- vorhandene Systeme,
- gewünschtes Ziel.
Diese Daten werden nicht sofort vollständig automatisiert weiterverarbeitet. Sie landen zuerst in einer strukturierten Datenpflege- und Anreicherungsschicht.
Dort können sie geprüft und ergänzt werden:
- Ist die Anfrage vollständig?
- Ist das Thema richtig kategorisiert?
- Ist eine Rückfrage notwendig?
- Gibt es bereits einen bestehenden Kontakt?
- Welche Priorität hat der Vorgang?
- Wer ist zuständig?
- Soll ein Erstgespräch angeboten werden?
- Ist der Datensatz bereit für die Weiterverarbeitung?
Erst wenn der Datensatz ausreichend qualifiziert ist, übernimmt n8n.
n8n kann dann:
- einen CRM-Eintrag erstellen,
- eine Aufgabe anlegen,
- eine E-Mail vorbereiten,
- eine KI-Zusammenfassung erzeugen,
- einen Antwortvorschlag erstellen,
- ein Ticket erzeugen,
- interne Benachrichtigungen versenden.
Der entscheidende Punkt ist:
n8n arbeitet nicht mit rohen, unklaren Eingaben, sondern mit vorbereiteten und geprüften Daten.
👤 Der Mensch bleibt Teil des Prozesses
KI und Automatisierung bedeuten nicht, dass Menschen aus dem Prozess verschwinden.
In vielen Fällen verschiebt sich ihre Rolle.
Menschen müssen nicht mehr jede Information manuell übertragen. Sie müssen nicht mehr dieselben E-Mails schreiben oder Datensätze doppelt pflegen.
Aber sie bleiben wichtig für:
- Bewertung,
- Plausibilitätsprüfung,
- Freigabe,
- Priorisierung,
- Verantwortung,
- Umgang mit Sonderfällen.
Eine gute Architektur entlastet Menschen von Routinearbeit, ohne ihre Verantwortung zu umgehen.
Das ist besonders wichtig, wenn KI im Prozess eingesetzt wird.
KI kann einen Vorschlag machen.
Ein Mensch kann prüfen und freigeben.
n8n kann anschließend zuverlässig ausführen.
👤 Automatisierung ersetzt nicht Verantwortung. Sie sollte Verantwortung besser unterstützbar machen.
📌 Warum solche Werkzeuge nicht veraltet sind
Man könnte meinen, Formulare, Tabellen und strukturierte Eingabemasken seien im KI-Zeitalter weniger wichtig.
Das Gegenteil ist der Fall.
Sie werden wichtiger, weil sie den Rahmen schaffen, in dem KI sicher und sinnvoll arbeiten kann.
Ohne Struktur entsteht ein Prozess, der stark von Interpretation abhängig ist. Mit Struktur entsteht ein Prozess, der nachvollziehbar und steuerbar bleibt.
Formulare, Dialoge und Datenpflegewerkzeuge sind deshalb keine Überbleibsel aus der Vor-KI-Zeit.
Sie sind die Qualitätssicherungsschicht vor der Automatisierung.
Oder anders gesagt:
KI macht strukturierte Daten nicht überflüssig. KI macht ihren Wert sichtbarer.
❌ Typische Fehler bei KI-gestützter Automatisierung
In der Praxis treten häufig ähnliche Fehler auf.
1. Zu früh automatisieren
Daten werden direkt nach der Eingabe weiterverarbeitet, obwohl sie noch nicht geprüft wurden.
Das führt dazu, dass fehlerhafte oder unvollständige Informationen in Zielsystemen landen.
2. Freitext überschätzen
Freitext ist flexibel, aber schwer kontrollierbar. Wenn alles in einem großen Textfeld landet, muss die KI zu viel interpretieren.
Besser ist eine Kombination aus strukturierten Feldern und ergänzendem Freitext.
3. KI als Reparaturwerkzeug für schlechte Prozesse nutzen
Wenn der Prozess unklar ist, soll die KI ihn „verstehen“. Das kann kurzfristig funktionieren, erzeugt aber langfristig schwer nachvollziehbare Automatisierung.
4. Keine Freigabestufe einbauen
Nicht jeder Vorgang sollte sofort automatisch weiterlaufen. Gerade bei Kundenkommunikation, Angeboten oder sensiblen Entscheidungen ist eine Prüfstufe sinnvoll.
5. Keine saubere Datenbasis speichern
Wenn nur Eingaben direkt durch Workflows geschoben werden, fehlt später oft die Übersicht: Was wurde erfasst? Was wurde ergänzt? Was wurde an die KI übergeben?
Eine Datenpflege- und Anreicherungsschicht schafft hier Transparenz.
🧭 Was gute Datenanreicherung leisten sollte
Eine gute Datenanreicherungsschicht vor n8n sollte mehrere Aufgaben erfüllen:
Erfassen:
Daten strukturiert aufnehmen
Prüfen:
Pflichtfelder und Plausibilität kontrollieren
Ergänzen:
fehlende Informationen nachtragen
Kategorisieren:
Thema, Priorität und Zuständigkeit festlegen
Freigeben:
bewusst entscheiden, wann ein Workflow starten darf
Dokumentieren:
nachvollziehbar halten, was verarbeitet wurde
Übergeben:
Daten sauber an n8n weiterreichen
Erst durch diese Schritte wird aus einer Eingabe ein belastbarer Prozessauslöser.
🔗 Die eigentliche Stärke liegt im Zusammenspiel
Der größte Mehrwert entsteht nicht durch ein einzelnes Werkzeug.
Er entsteht durch das Zusammenspiel:
- Menschen liefern Informationen.
- Formulare und Dialoge strukturieren die Eingabe.
- Datenpflegewerkzeuge sichern Qualität.
- n8n orchestriert den Prozess.
- KI unterstützt bei Analyse, Text und Klassifikation.
- Zielsysteme erhalten verwertbare Ergebnisse.
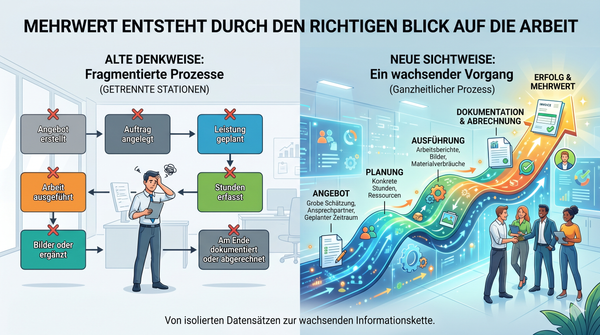
Das ist eine andere Sicht auf Automatisierung.
Nicht mehr:
Eingabe rein → Workflow raus
Sondern:
Eingabe
→ Struktur
→ Anreicherung
→ Qualitätssicherung
→ Automatisierung
→ KI-Unterstützung
→ Ergebnis
Diese Architektur ist robuster.
Sie ist besser wartbar.
Und sie passt besser zu verantwortbarer KI-Nutzung.
🏁 Fazit: Gute n8n-Prozesse beginnen vor dem Workflow
KI verändert Automatisierung grundlegend. Sie macht Prozesse leistungsfähiger, flexibler und intelligenter.
Aber KI hebt die Notwendigkeit guter Datenqualität nicht auf.
Im Gegenteil: Je stärker KI in Geschäftsprozesse eingebunden wird, desto wichtiger wird die Frage, auf welcher Datenbasis sie arbeitet.
Formulare, Dialogsysteme und strukturierte Datenpflege sind deshalb nicht veraltet. Sie bilden die Grundlage dafür, dass KI in Automatisierungen zuverlässig, nachvollziehbar und verantwortbar eingesetzt werden kann.
n8n bleibt dabei die zentrale Orchestrierungsschicht.
KI unterstützt bei Bewertung, Zusammenfassung, Klassifikation oder Textgenerierung.
Die Qualität entsteht jedoch schon vorher: bei der strukturierten Erfassung, Anreicherung, Prüfung und Freigabe der Daten.
Ein guter Workflow beginnt nicht mit einem Prompt.
Er beginnt mit der Frage:
Sind die Daten gut genug, um darauf zu automatisieren?
Genau deshalb bleiben spezialisierte Open-Source-Werkzeuge zur Datenanreicherung auch im KI-Zeitalter relevant. Nicht als Ersatz für n8n. Nicht als Konkurrenz zur KI. Sondern als Qualitätsgrundlage für beides.
🏁 Die eigentliche Stärke moderner Automatisierung liegt nicht darin, alles sofort automatisch zu machen. Sie liegt darin, Daten so gut vorzubereiten, dass Automatisierung und KI verlässlich arbeiten können.
Gerd Kopp ist Wirtschaftsinformatiker, Ex-CIO und unabhängiger Interim Manager und Berater für den Mittelstand. Seit 2020 begleitet er Unternehmen bei IT-Governance, Organisationsentwicklung und dem Aufbau tragfähiger Strukturen – dort, wo schnelles Wachstum auf fehlende Fundamente trifft. Ein Schwerpunkt seiner aktuellen Arbeit liegt auf dem sinnvollen Einsatz von KI in Unternehmen: nicht als Hype, sondern als strukturelle Frage – wer entscheidet, wer verantwortet, wer kontrolliert.
Er schreibt über das, was er in der Praxis sieht: ohne Weichzeichner. Weitere Beiträge gibt es auf gerds-blog.de. Wer mit ihm arbeiten möchte, findet ihn unter gerds-it.de.